There are some big misconceptions out there about how nofollow works, so let’s clear it up.
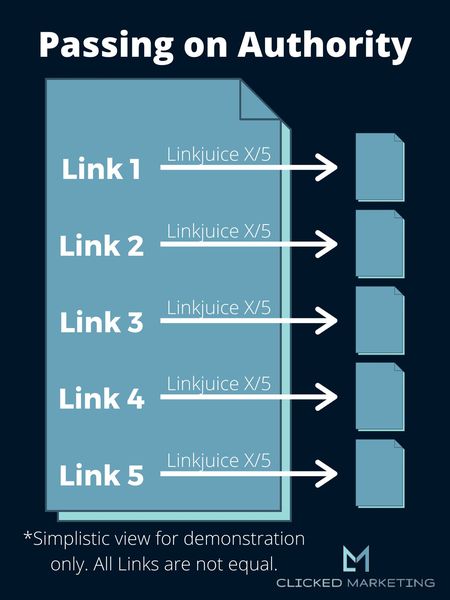
The first image is a simplified version of how a page passes on authority to other pages through its links.
Each page has a set amount of linkjuice that it can pass on through its links.
When nofollow was first introduced, it blocked that linkjuice from passing through links carrying the nofollow tag, and it would instead be redistributed among the remaining links on the page, making them stronger, as shown in this image.
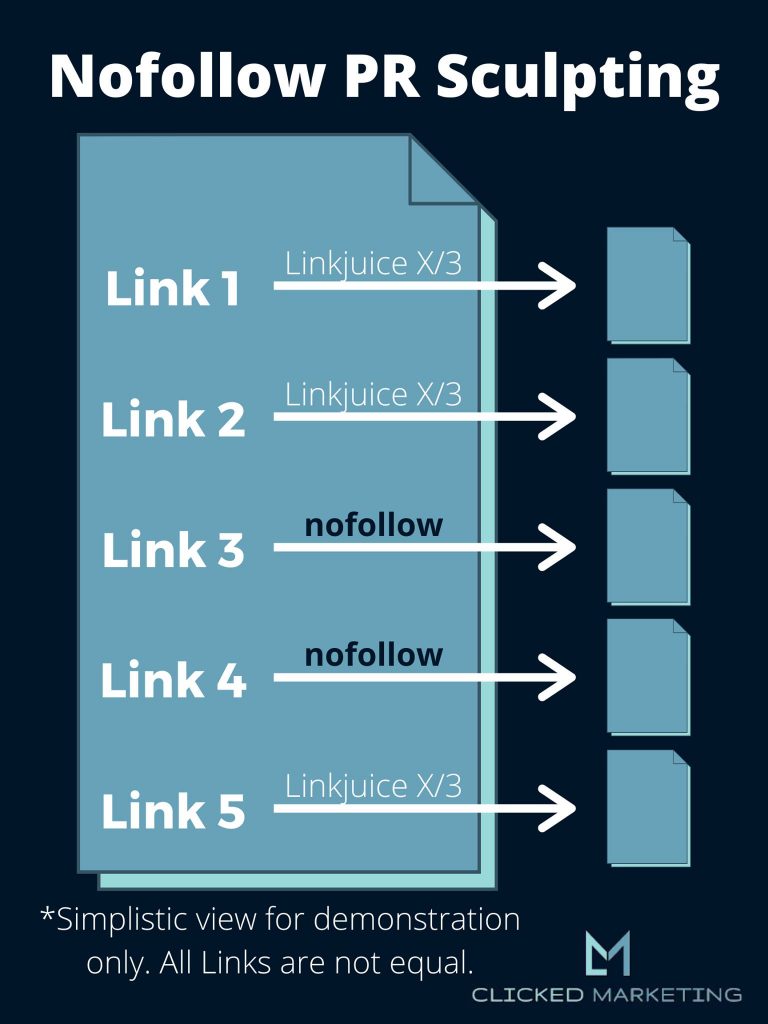
Many of us used this for what was known as PageRank sculpting. We could control the flow of linkjuice throughout our sites to boost the pages we really wanted to rank.
Of course, Google didn’t like that, so in 2009 they changed how they handled nofollow.
This is how they handle it now.
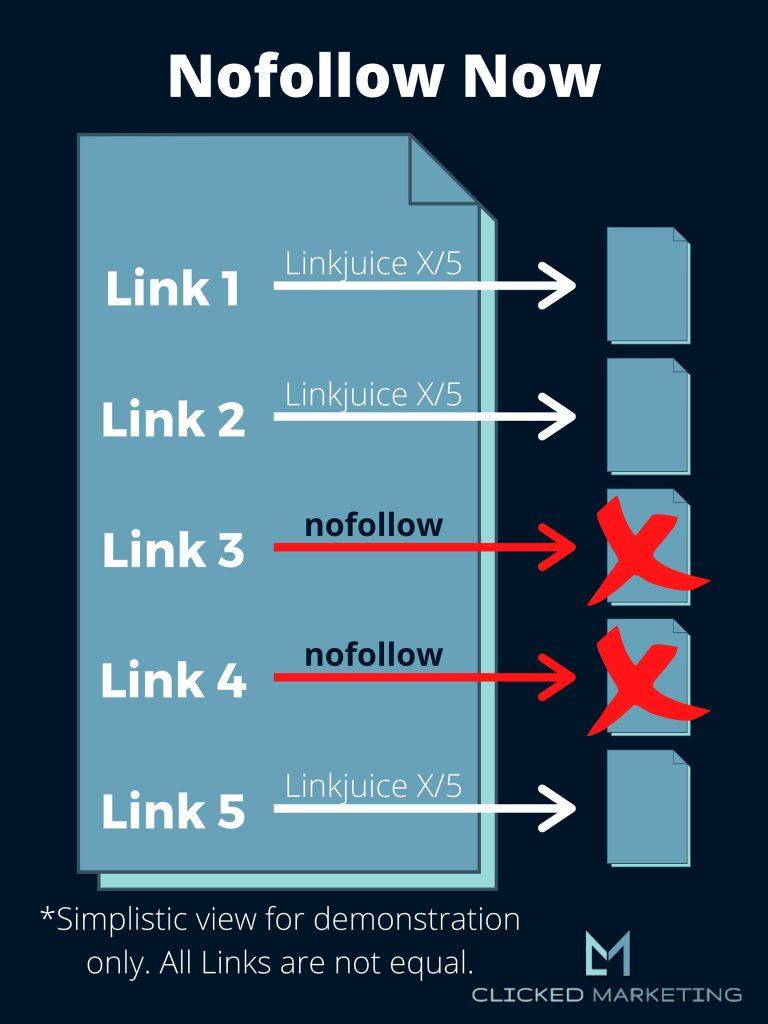
Linkjuice still flows through links tagged as nofollow. It no longer gets redistributed among the remaining links on the page, but it does not get credited to the target page they are linking to.
This is why it is a bad idea to nofollow internal links. You are actually bleeding out linkjuice by doing so.
For some reason, people still think Google treats nofollow as illustrated in the first image, but that has not been the case since early 2009.
Then there was the update in March of 2020, where Google again changed how they treat the nofollow tag. Up until then, it was treated as a directive. With the latest update, they instead treat it as a hint or request. They make up their own mind whether to treat a link as nofollow or to ignore the tag. They will never tell you if you they are obeying the nofollow tag or not on any links, so we have no idea if a link is really nofollow or not.
They also added additional identifiers they want webmasters to use to identify sponsored links, affiliate links, etc.
Can you still sculpt PageRank?
Some of the min/maxers out there who really want to squeeze out every little value they can have found ways to sculpt PageRank even after Google changed how they handle nofollow.
For a long time, Google had trouble parsing javascript. A common technique was to put lower-value links inside javascript code so that Google could not see them. People would do this for links to things like contact us, privacy, and terms of service pages.
Google has gotten better at reading javascript, so this method really does not work anymore.
The other way it was commonly done was to use iframes. Googlebot always skipped over iframes, so you could use them to hide links with less importance and sculpt PageRank that way. For years, the footer and parts of the header of Bruce Clay’s site used iframes to do this.
Google does seem to read the content inside iframes these days, although I have seen some tests where they did so inconsistently. This method could still work, but it’s just not 100% reliable.

