A topic that comes up frequently on consulting calls is “How do we get Google to index our content?”
I’ve seen cases where organizations have launched a brand new section on their site, dumped huge amounts of resources into it, only to find not that they are having challenges ranking the content, but that they can’t even get Google to index it.
So why today am I talking about preventing search engines like Google from indexing your content?
Well, there are cases where you want to prevent search engines from displaying content in their SERPs.
Some examples include:
- ad landing pages
- premium content for members only
- user generated content
- new pages being designed (although this should really be done in a staging environment)
- staging environments
- thank you pages
The mistake
The most common mistake I see websites make when trying to prevent content from being indexed is to rely on a robots.txt file and direct search spiders to not crawl the pages.
This is a mistake because it won’t actually prevent content from being indexed. Yes, it will prevent spiders from crawling those pages, but not indexing them.
I’ll show you an example of a site that tried this method. I have to block out the URLs for confidentiality reasons, but you can clearly see what is going on here.
They allow user generated content on their site in a directory listed as /p.
To prevent this content from being indexed, they used robots.txt.
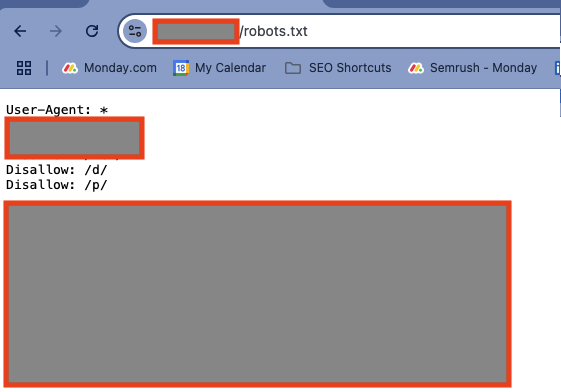
Only, that didn’t work.
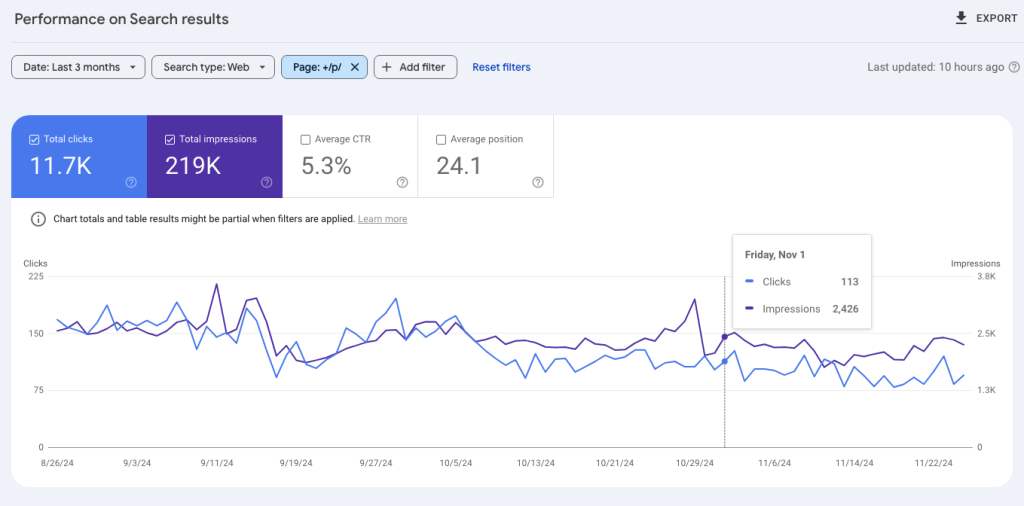
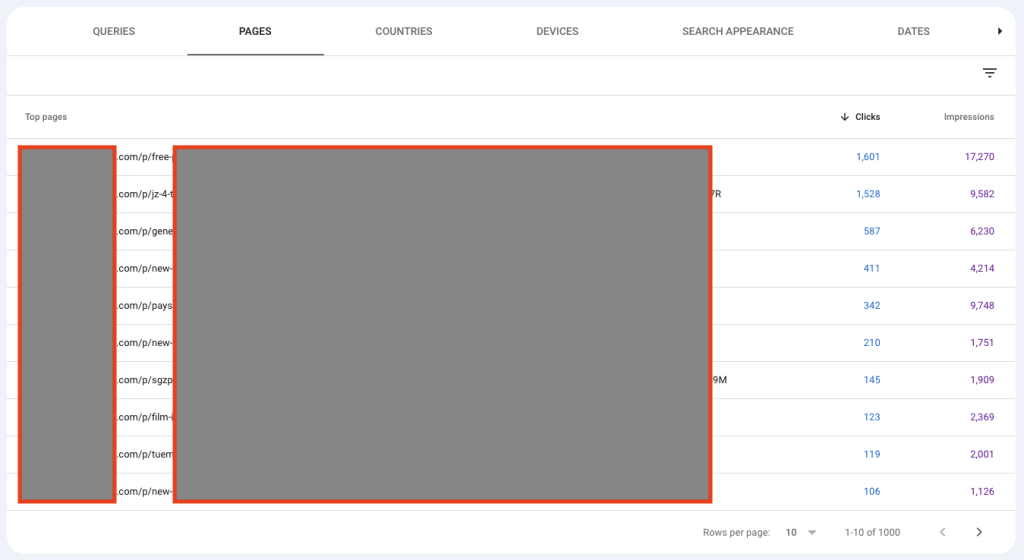
These pages are still being indexed.
But if they are restricted by robots.txt, how does that happen?
It has always been this way. The reason behind it is if that Google finds another path from an external source to these pages, i.e. if another site is linking to a page blocked by robots.txt, Google will often index the content.
They explain this themselves in their documentation.
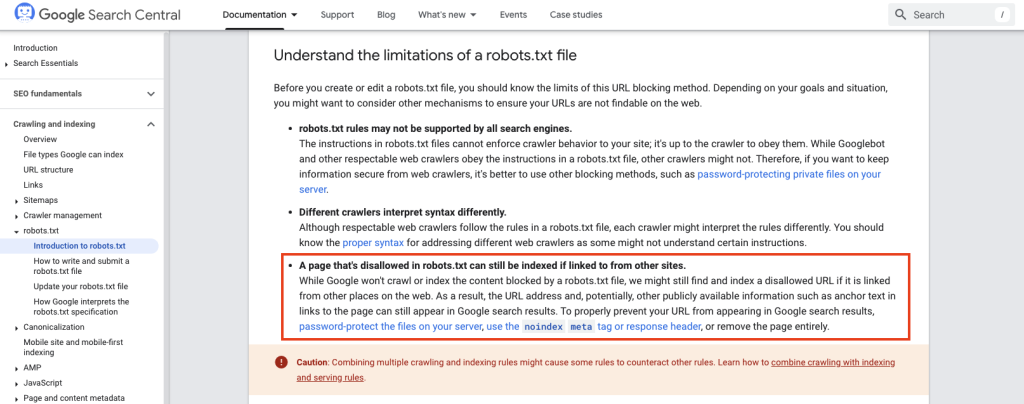
That may sound a little confusing. Google says they won’t crawl or index the content, but they can still index the URL.
In other words, they are not reading the content of the page. You won’t see the title tag or a meta description show up in search results, but the URL can still show up.
And as you can see in the above images, even without Google being able to read the content of these pages, they can still rank and get clicks.
This is happening in this case because the users who are creating these pages are also building links to them. They are trying to use the site for parasite SEO, which could very well lead to a manual action in the future for the site.
The second mistake
You have to add a noindex tag to these pages. This site did that.
Then why are the pages showing up in the SERPs?
This is another place where a lot of sites get it wrong…
They are being indexed because of the block in the robots.txt file.
Here is what happened.
When Google’s crawler crawled the site, it saw the block on robots.tx and did not crawl these pages.
However, Google’s spider later found links on other sites pointing to these pages. It followed those links, but because of the robots.txt restriction it couldn’t read the content of the page, including the noindex tag.
Because of the amount of links pointing to these pages, Google decided the URLs were worth indexing.
The proper solution
The correct way to handle this is actually very simple.
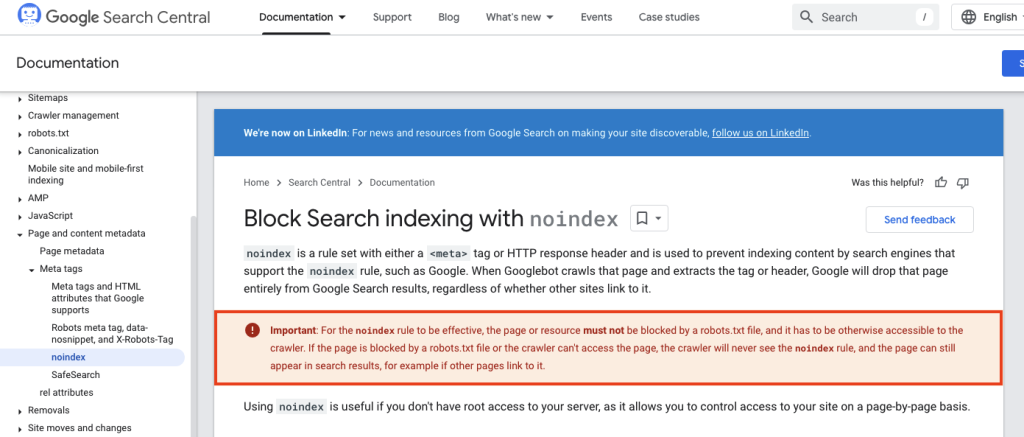
The way to prevent this from happening is that you must have noindex tags on pages you do not want search engines to index, but you must not restrict the crawling of those pages.
Search engines need to be able to read the noindex directive.
Google also covers this exact point in their own documentation.