First, I’m not going to bore you with the details and retelling of the story of this leak. If you haven’t read that already, I would encourage you to go read Rand Fishkin’s telling of the story about how these documents were shared with him.
You can also view the docs yourself here.
A few things we should get out of the way.
First, I know there is a lot of conversation and outrage going on about Google “lying” to us over the years. To be honest, it feels a lot like many of the silly causes taken up on Twitter over the past few years for everyone to rally around and get Twitter-pissed about.
Personally, I think we have always known they were lying to us at times. I think they try to be honest as much as they can, but there is only so much they can share without giving away too much of the algorithm.
I saw in Mike King’s analysis he suggested that Googlers should sometimes say, “We can’t talk about that.”
I don’t think that works though unless they use that as their answer for everything, which we don’t want either. Otherwise, when they are asked something and respond with, “We can’t talk about that,” they would be indirectly confirming what was asked, would they not?
Second, there is no weighting given to any of these features being stored by Google. I don’t think we can call all of these ranking factors. Some certainly are. Some are ranking systems. Some are metrics used within ranking systems. And others we don’t know exactly what they are.
But there are no values assigned to any of them within these documents. From these documents alone, we have no idea how heavily one is weighted against another.
Let’s get into it.
There are over 14,000 features in the leaked documents. That’s a lot of information to go through. We are just scratching the surface at this point.
Links are still important
I’ll just leave it at that.
My Take: As many of us already knew, the recent conversations around the demise of links were premature.
There are indexing tiers and they may impact link quality
Google has its index separated into tiers. The most important and most frequently updated content is stored in flash memory. Less important documents are stored on SSDs. Infrequently updated content is stored on HDDs.
This is likely for cost savings. HDDs are much cheaper than SSDs, and SSDs are much cheaper than flash memory, especially at the scale of Google’s entire index.
It’s stored as sourceType.


What this indicates is that links from pages indexed in the higher tier are more valuable than links from pages indexed in the lower tier.
My Take: It is interesting that Google uses this indexing tier system in its evaluation of links. I don’t think this changes any of our behavior though. Obviously, we have always valued links from other high ranking sites or popular news sites.
Font size and weight may matter
Google is tracking the average weighted font size of terms in documents.
Bolding important terms and passages and/or making them larger may be to your benefit.
They are also tracking this for the anchor text of links.
My Take: What would happen if you made the anchor text of all your internal links 1-2 pixels greater than the text around them? And could enlarging the font size of a passage increase its change of showing up in a featured snippet you are targeting?
Site Authority is a thing
Despite Google denying for years that they have any kind of domain authority metric, they do indeed track something called siteAuthority.
My Take: We don’t know how it is used or what it may be used for.
One possible use that jumps out to me and makes a lot of sense is they could use it to determine if they should trust a new piece of content on a site right away or if they should wait to collect more signals.
That would make a lot of sense and explain why some sites can publish content that ranks highly right away, while other sites can publish content that will rank highly but there seems to be a definite delay in it getting there.
Google is tracking authors
Google is storing authors for pages.
Before all of you EEAT fans head off for your victory lap, remember we don’t know if they are actually using them for anything. All we know is that they are tracking them.
Mike King found in his analysis that they are also trying to determine if an entity on the page is also the author.
It looks like there is some sort of measurement of authors going on, but also this could all just be left over from the Google+ authorship days.
They also could be not utilizing it but tracking it in case they decide to in the future.
My take: It wouldn’t hurt to use authors for your non-service page content, but I would say if you are going to do it, do it right. Build out a true author page. Try to get the author into the knowledge graph.
Anchor text mismatches may be a problem
There appears to be a demotion of link value when a link does not match the target site it is linking to.
My Take: Google wants to see relevance in the source of a link and the target page it is linking to.
Be careful about this. It doesn’t necessarily mean that irrelevant links are useless, or, as I saw someone else say, that they can hurt your site.
That is not what this is saying at all. It just means that the link is passing on less value than it could be.
SERP Demotion
Another demotion signal that showed up in the document was a SERP demotion. This is likely based on data collected from user behavior in the SERP, i.e. searchers clicking on a result and then going back to the SERP to click on another one.
My Take: We have often speculated that searchers bouncing back to the SERPs to click on another result could be a negative factor in some searches.
I would guess this likely excludes shopping queries or other queries where searchers are more likely to visit several pages.
Google is definitely using click data
This one was confirmed in the recent DOJ antitrust trial where the existence of a ranking system known as NavBoost was revealed. NavBoost uses click data to boost or demote a rankings.
This isn’t something new either. It was confirmed in that trial that NavBoost has been around since 2005. At that time it was using an 18 month rolling period of data. Recently that was updated to a rolling 13 months of data.
The summary of the NavBoost module in the leaked documents refer to it as “click and impression signals for Craps”.
Craps is the current state of the Google SERPs.
Just kidding. Making sure you are still paying attention.
Craps is one of the ranking systems within Google.
There are also things like good clicks, bad clicks, and unsquashed clicks referenced in the documents.
My Take: Not only is Google using click data but the leaked documents indicate it goes deeper. They are also storing information like which search result had the longest click during a session.
Google is using clicks on search results and information it collect on what those users do after they click as part of its ranking algorithms.
This really isn’t much different than Google using links as votes. Clicks can be user votes as well.
Google is using Chrome data
Google is using a site-level measure of views from Chrome.

My Take: I’m not sure what good a site-level measure of views from a Chrome browser would be. There are likely other ways Chrome data is being used.
There are 47 mentions of ‘chrome’ in the document including mentions of ChromeOS and Chromecast. There is also mentions of chromeTransCount, chromeTransProb, chromeWeight, chrome_trans_clicks, and uniqueChromeViews in the document.
I mean why wouldn’t they use Chrome data? You don’t develop the #1 browser in the world and give it away for free for no reason.
Titles are matched against search queries
There is a feature called titlematchScore that is measuring how well titles are matching search queries.
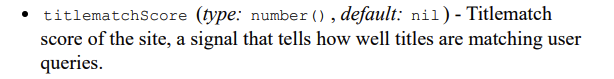
My Take: Trying to create a catchy title tag that you think will get a better click through rate may not be the best idea. Match your title with the primary search focus you are targeting.
Ranking for many queries is a signal.
I won’t go into the weeds here too much, but between NavBoost, click data, and a few other features there appears to be a benefit given to content that drives more clicks across a broader range of search queries.
My Take: SEO Avalanche Theory confirmed.
That is enough to unpack for this round. I will likely have more next week or in other upcoming notes.


